Contents
The requirement for model analysis for Ptolemy II arises from the implementation of backtracking. It turns out that, to implement incremental backtracking in a clean way, actor code must be analyzed first. This is a source-level program analysis. This article argues that once an appropriate analysis is available, backtracking can be implemented very efficiently, and the same analysis can also be the backend of model checking for Ptolemy models.
The basic scheme of incremental backtracking under implementation is described in Backtracking in Ptolemy II. In this approach, the backtracking sub-system only records the subsequent changes done in the model once a checkpoint is created. When the model needs to roll back to its previous state, the backtracking sub-system restores the old values to all the places that have been changed.
AspectJ was used to
capture such changes. For example, when we weave an aspect with a
field f of class C, we can
dynamically detect every assignment to f, before which
its old value is stored in a backup buffer. However, this
method using AspectJ has important limitations:
This requires building Ptolemy with AspectJ, which is not as fast or user-friendly as native Java compilers.
There are certain changes that AspectJ cannot precisely capture. For example, the assignment to an element in a large array (
A[5] = 1). As discussed in Backtracking in Ptolemy II, AspectJ only detects that the reference of arrayAis fetched. It does not return any information about which element is changed (in this case,A[5]), or the new value of that element.An aspect must be written for every actor class. Though aspects can be generated automatically, the method used to generate those aspects requires model analysis on actor code (e.g., to detect the state variables defined in each actor). In the most general case, this analysis is not any simpler than the one we are going to see.
Naturally, we would like an approach that does not require AspectJ at all. In the following sections, I am going to propose an improved method that analyzes the actor classes, detects state variables, generates extra code for each state variable by modifying the program AST (Abstract Syntax Tree), and then regenerates Java code with backtracking support added. The regenerated code can then be compiled with native Java compiler.
Before getting started, an important assumption must be made clear: State
variables are all private class members so that their
values cannot be changed directly from outside of the class. This assumption allows us
to modify one class at a time. We could as well modify the following method
to also manage non-private members. There is a trade off
between how complex our analysis should be, and how powerful our method is
expected.
Requiring all state variables to be private also helps
develop a good coding style for Ptolemy actors. The same rule has already
been followed.
The model analysis method is derived from Java program analysis, because in Ptolemy,
actors (and directors) are directly written in Java, following certain rules (e.g.,
the prefire-fire-postfire
sequence). This makes analysis more challenging, because Java source analysis is
usually harder than model analysis in a specific domain and in a specific modeling
language (e.g., UML).
There always exists the tradeoff between power and complexity, which is important to our design.
The big picture of the proposed method is illustrated in Figure 1, “The big picture”. The important steps are made clear below:
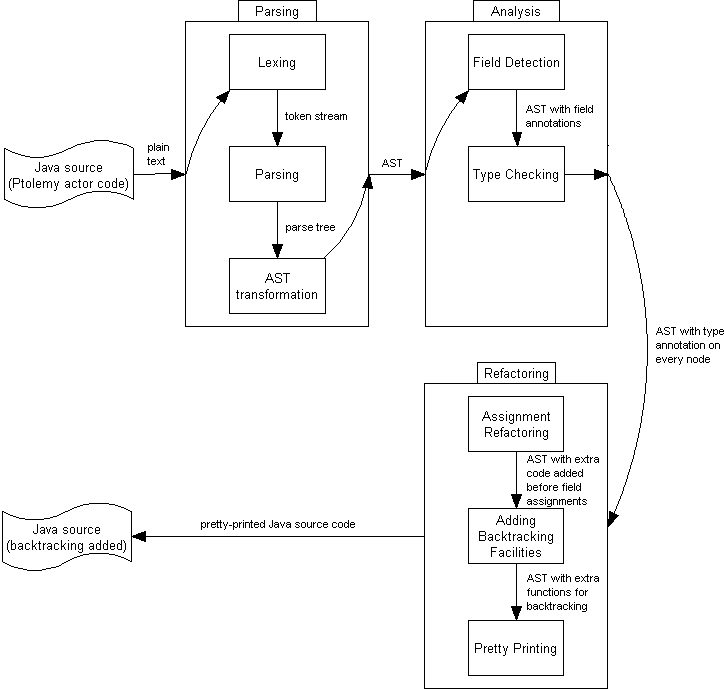
As the input being Java source written in plain text files, a parsing step is taken first. This is an ordinary program parsing, which is not interesting to our discussion. Currently, the parser in JRefactory is being used. This parser is generated by JavaCC from the most recent Java 1.5 Grammar. The internal steps taken by the parser is included in the figure for the sake of completion: a lexer divides a source file into a token stream; a parser parses the token stream and builds a parse tree; and an AST transformer converts the parse tree into an AST [1].
-
Analysis can then be done on the AST, which represents the complete structure of the Java code. This analysis is currently divided into two phases. (More phases may be added in the future.)
For backtracking purpose, naturally, fields in each class must be detected. This is relatively simple: We simply walk through the AST and look for every class defined in the program. For each class found, loop over its members and look for
privatefields. We then annotate the AST with those field information.Three complications arise after a careful thought. Since Java allows nested classes, the following situations must be taken care of:
-
Non-
publicclasses (Bin the following example) in the same file (A.java):public class A { } class B { private int i; } -
Nested classes (
Bin the following class):public class A { class B { private int i; } } -
Subclassing at instantiation:
new A() { private int i; };
In all the above cases, we want to derive field
i. In case 1,ibelongs to classB; in case 2, it belongs to classA$B; however, in case 3, it belongs to a class with a name that is compiler-dependent. -
-
After gathering enough information for each field, we are going to type-check the AST. We can safely assume that the source input contains no type errors (because it can be compiled with Java compiler before we analyze it). Hence, this type checking phase is just to derive appropriate types for each expression without producing any error. The intention is made clear with the following examples:
public class A { ... private int i; void func() { List list; ... ((A)list.get(0)).i = 1; ... } ... }Clearly, the old value of
ishould be recorded before this assignment operation is performed. The analyzer can easily detect that(A)list.get(0)returns an object ofAbecause of this explicit type conversion (note thatlist.get(0)returnsjava.lang.Object).public class A { ... private int i; void func() { B b; ... b.getA().i = 1; ... } ... }Unfortunately, in this second case, it is not so clear whether
ishould be monitored or not. To make a decision, the analysis must be taken across different classes, i.e., to analyzeBalso and discover the return type ofgetA(). -
After analysis is performed, assignments to fields can be refactored. In our case, this refactoring is merely adding code related to value backup before assignments.
publicfunctions are also added to classes during the refactoring step. Those functions can be called from the outside to create checkpoints, to roll back to a previous state, or to discard previously created checkpoints. When refactoring is done, the AST is then converted back into Java source, and Java compiler is used to compile the source into byte-code. If a compiler backend (e.g., soot) is provided, the output from AST may be byte-code directly.
Using the above program analysis approach, potentially powerful model checking can be implemented for Ptolemy.
Low-level model checking for Ptolemy was hard, because Ptolemy models were built from actors and directors, which were directly written in Java. Clearly, an actor written in Java can do anything, including performing such operations that violate important rules. It can be compiled with Java compiler and then be loaded into a Ptolemy model. The model can be executed afterward. In this whole process, no warning or error is given to the user.
An example of bad operations performed by an actor is committing its state in the
fire method
[2].
Another example is made possible by the collection design in Java 1.4 and earlier. Suppose a director
keeps a List of the actors that it is interested in. Any arbitrary object can be
added to the list, whether it is actually an actor: Java 1.4 or earlier does not type check this.
When the director retrieves an actor from the list, it explicitly converts it into
Actor type or any subtype.
Yet another example is a subtle and more semantic one. Suppose an actor is designed to produce output for each firing. It is very easy to design an actor that fails to produce an output in rare cases (including when an exception occurs).
There can be many semantic errors in an actor, even if it compiles, loads into a model, and runs for quite a long while. Generally, there is no guarantee that an actor is free of certain kind of bugs without source-level analysis.
With the analysis discussed above, we can check the AST according to a set of pre-defined rules.
For example, once the analyzer detects all the state variables of an actor, it may check the
fire function and some of the other called functions to see if any state
variable is modified. If the convention is not followed, it may reject the actor or merely produce
a warning.
Actor designers may also provide annotations that help the analyzer. For example, when an actor
has a List as its state variable, the designer may explicitly annotate the
type(s) of the elements that can be added to the list. This annotation can be written as a comment
for backward compatibility, or as a template introduced by Java 1.5.
To make sure that output is produced for each firing, the analyzer may walk through each
executable path in the fire method to see if there is any
path along which the actor may not produce any output. This analysis is
conservative in that deciding executable paths is NP-complete, as the following
example shows:
if (very_complex_computation()) {
produce_output_on_channel(0);
} else {
}
However, the analyzer is always able to give some hints to the designer.
[1] AST is a compact form of parse tree which omits many intermediate nodes. It turns out that JRefactory only gives us parse trees, which are harder to analyze or modify, rather than ASTs in a strict sense.
[2]
According to Ptolemy convention, an actor may receive input and produce output in its
fire method. However, it can only commit a change of state in its
postfire method. This makes it possible to fire an
actor multiple times and then commit its state only once.