Contents
This sub-project aims to develop an efficient incremental backtracking mechanism to be used in Ptolemy II.
A backtracking facility enables the system to restore its old state. It has many applications in practice, and is especially important to high-performance distributed computation.
In developing this sub-project, we highlight the following (increasing) list of criteria:
Performance. The highest priority is awarded to the performance of the resulting system (the Ptolemy II system with backtracking support built in), as compared to the original system. Novel approaches are employed mainly to improve performance, with moderate complexity added.
Automatic transformation. Transformation from the original system to the backtracking-enabled system must be automated as much as possible. Due to the size of the existing system, it is not realistic to require a manual recoding in most of its sources. Moreover, coding the backtracking sub-system by hand makes it hard to debug and evolve over time.
Clean interface to other parts. The backtracking sub-system must reveal a small but powerful interface to the other parts in the system. It provides the users with functions such as creating checkpoints, undoing multiple language-level operations by backtracking to a previous checkpoint, and even redoing those operations to achieve some form of laziness.
Here are some screenshots adopted from the last attempt of backtracking in Ptolemy II.
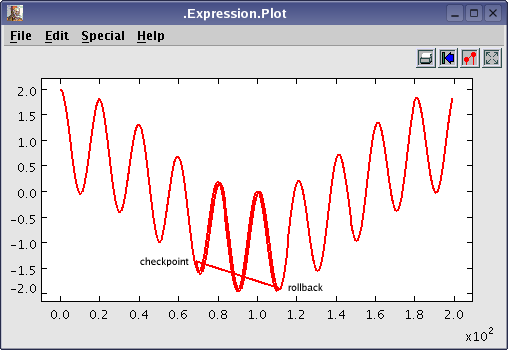
Figure 1, “An execution of the Expression demo with backtracking” illustrates an execution of the Expression demo, distributed in the latest release of Ptolemy II. Backtracking is added to the release with little human interaction. As a result, we can control the execution by creating checkpoints at certain point in time, and later roll back the whole system.
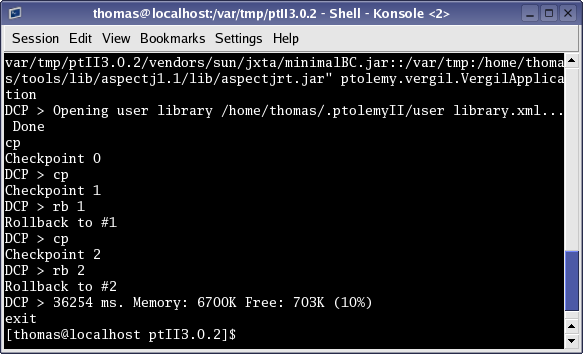
Figure 2, “An execution of the Expression demo with backtracking” shows the console, manually modified from the Ptolemy II interface to allow users to control the above backtracking process.
Careful readers may notice that the two traces in Figure 1, “An execution of the Expression demo with backtracking” (the one drawn for the first time and the one drawn after a backtracking) do not match exactly, while they should. This is due to a lack of synchronization among running threads, as will be discussed below.
Several observations are made here. They are important to the understanding of this mechanism.
Java is a statically typed language. This implies that a large part of necessary information (mostly importantly, type information) can be obtained at compile time.
Any observable side effect is caused by assignments. We do not take care of any other traditional types of side effect, such as that caused by system calls, inter-language interaction (via JNI), communication with peripheral devices, disk input/output, and so on. The only type of side effect that we are interested in, is caused by assignments, either to local variables or to attributes belonging to certain classes.
-
However, an assignment may escape the scope where the target object is defined. A common example is, an object locally defined in a method is passed to another method as a parameter, and its attributes get changed in the callee.
This gives rise to difficulty in our static analysis.
Every datum is essentially a pointer, except the values of the 8 basic data types:
byte,short,int,long,float,double,char, andboolean. This property makes it easy to implement analysis and backtracking in general, and also include those primitive data as special cases.
AspectJ is used as a major tool. Aspect-oriented code is automatically generated to capture the assignments in the system. This code is fed in to AspectJ and is then woven with the original code. The resulting system (which does not require any support other than JRE to run) is backtracking-enabled. Users of the system or the system itself may use functions provided by the backtracking interface to manage checkpoints.
In order to automatically generate aspects, the classes in the original system is statically analyzed with JavaCC. It takes a Java grammar and manages to parse the Java source code. The output is an XML specification of attributes in the classes, with which aspects can be generated according to a common template.
Backtracking is used here as a general term for the facility that takes the job of saving certain states of the system and restoring those states on request. [1] Literally, it merely refers to restoring the saved states so that no interesting difference can be observed. This is also called rolling back the system in software fault tolerance. A record of saved states is called a checkpoint. When used as a verb, checkpointing refers to saving such a record, with the storage unspecified (the inverse of backtracking or rolling back).
The major steps involved in the analysis and the transformation is listed as follows:
Prepare a runnable copy of the Ptolemy II source code.
Manually write a profile with some class names listed in it. In later steps, backtracking aspects will be generated to support those classes (and only those classes).
Use JavaCC to generate XML descriptions for the classes listed in the profile. Each description contains the attributes declared in the corresponding class.
Manually edit the descriptions to remove those attributes that need not be taken care of. For example, a ball in a space may have a pointer to the space as its attribute. We do not want this attribute to be traced when the ball itself is backtracked; otherwise, the space would also be backtracked, and also the other objects in that space.
From the modified descriptions, automatically generate aspects for AspectJ. Those aspects are formed according to a set of templates.
AspectJ, instead of Java compiler in the JDK, is used to compile those aspects with Ptolemy II source code, and thus produces the final system.
Since every run-time object in Java can be regarded as a pointer, the backtracking sub-system only needs to keep track of pointers. It restores saved pointers to the original attributes or variables when backtracking is requested.
Storing pointers is much faster than storing the content of objects. In a run of a Java program, pointers of an object can be regarded as fixed value. Assignments of attributes from one object to another is pointer copying. The backtracking sub-system traps such assignments (by means of aspects) and backup the old values if a checkpoint has been created. When backtracking is requested, the stored pointers are restored. (We ignore values of the basic data types in a large part of this discussion, because they can be easily treated as special cases.)
Obviously, as compared to serialization, this scheme is much more efficient. It is also easier to manage, because when serialization is used, a stored pointer may become meaningless at the time of backtracking. It is also hard to guarantee consistency when the previous content is restored to some of the currently existing objects, while the others are left unchanged.
A few problems are to be solved. Many of them relate to such a situation: it is much easier to backtrack the entire system than to backtrack just a part of it. However, the latter case is dominant.
The difficulty of backtracking only ``a part'' arises in defining exactly the boundary between the set of the objects to be backtracked (denoted by Ob(t) at time t) and the complement set (denoted by On(t)). Their disjoint union is the set of all the existing objects: O(t)=Ob(t)∪On(t). The rules defined to bi-partition O(t) are usually specified in a dynamic manner: the system designer usually identifies which objects to be backtracked rather than all the objects of which classes to be backtracked. Hence the difficulty.
According to the steps defined in the previous section, backtracking is directed by static analysis done at compile time. Classes are the natural entities in such an analysis. Dependency between classes (by means of the reference attributes defined in them) is traced so that when backtracking request is issued on class C, all the classes that C depends on backtrack first. This tree (or graph in practice) traversal is a post-order one.
In reality, system designers usually demand backtracking of semantic objects rather than classes. For example, it may be desired to roll back the state of a single actor in a model without modifying any other, even if it is of the same type. This requires an analysis of the dynamic structure, which cannot be done at compile time, and which is too expensive to do at run-time. Such an analysis at run-time also defects the real-time behavior of the execution (if it is designed to be real-time).
Let us now formalize the notion of this object-wise analysis for a single backtracking process:
Define root set R ⊆ O to be the set containing all the initial objects which the backtracking request is issued on. [2]
-
Let ref: t → O → 2O be the dependency function that relates objects at a certain time t to the other objects that they refer to in their attributes. For example, ref = {(t1,a,{b,c}),(t2,b,{a})} defines such a dependency that at time t1, object a refers to both b and c with one or more of its attributes; at time t2, the only dependency is b ← a. If it is clear from the context, we can omit the time dimension and treat ref as simply O → 2O.
Typically, ref can only be calculated at run-time. Even worse, the backtracking sub-system must compute the closure of ref to determine the whole set of objects to be backtracked. This computation becomes the major bottle-neck.
Even though the sub-system stores only pointers for future backtracking, it still incurs considerable extra memory consumption. Because old references are kept, objects cannot be garbage-collected once a checkpoint is created, until either all the previous checkpoints are discarded, or the system backtracks to some of the checkpoints.
This problem can be alleviated with several approaches, which also increase the complexity in implementation:
Not every assignment to an attribute is stored after a checkpoint is created. For example, if an attribute is changed 10 times after a single checkpoint is created, only the first assignment needs to be captured and recorded.
It may be possible to page out some of the saved objects to disk periodically. Since the backup information is used only in the same run of the system, it is also possible to page out pointers, if we can obtain them in some serializable form. [3]
Once the system designers are aware of this circumstance, the system that uses backtracking may be kept minimal, and checkpoints are created only when they are definitely necessary.
AspectJ has an inability in handling specific elements in an array. Consider the following statement:
A[10] = 1;
The optimal way to store the value of A[10] is to weave an
aspect of that specific element of the array with the original code. However,
Java handles arrays in its own way: it first fetches the pointer of the array,
whether the operation is a read or a write, then does the corresponding read or
write operation atomically with calculation and adjustment of the pointer. What AspectJ
captures is actually a fetch of the A object.
Hence, it may seem superfluous to weave the same aspect with the following statement also:
System.out.println(A[10]);
However, this seems indispensable: a fetch of A[10] is also
understood as a fetch of A; and if we want to handle the
previous case, we have to capture this fetch of the whole array, and back up
the while array (since we do not know even the index of the accessed element).
A simple flow-insensitive analysis in the source code seems to be a solution to the above problem. When an access to an element of an array is reached, extra code is added, which informs the backtracking sub-system of necessary information to only store the old value of that element alone.
Attributes are sometimes found defined in native Java classes, and many of those
classes are written in C++. This makes it absolutely impossible to keep track of
those attributes. Hashtable is such an example. No Java
based tool is capable of modifying its behavior in a well-managed manner.
Wrapper classes can be introduced to attack this problem. A new class
bc_Hashtable wraps the native Hashtable
class, and it signals the backtracking sub-system whenever values in the table are
changed (added, modified or removed). In this way, aspects need not be woven with
this class.
At any time in an execution of Ptolemy II, multiple threads run simultaneously. When a checkpoint is created, states of objects are stored regardless of the thread(s) that uses or owns it. However, when a backtracking operation starts, all the running threads must be paused at well-defined states. Otherwise, the result of the backtracking is unpredictable. (It may seem correct, it may seem wrong, but in most cases, the result seems just a little bit deviated from the truth, as it was in Figure 1, “An execution of the Expression demo with backtracking”.)
This makes implementation harder, especially because we want the backtracking sub-system to be added automatically. It also makes the resulting system unable to satisfy certain real-time requirements, because it can be temporarily frozen at the time of backtracking.
The problems discussed in the previous section do not prevent the use of this approach. Implemented carefully, this approach can be extremely efficient, automated and safe. In particular, several advanced implementation issues are considered here.
Laziness is desired in distributed computation. Consider an event-based system with several distributed components communicating with one another. When a time skew is detected in one of those components, backtracking is requested on it. As is clear from previous sections, this backtracking is accomplished by restoring all the saved pointers to the original attributes.
Suppose now that after the component is rolled back, the same sequence of messages since the checkpoint is received. It is not necessary to re-compute those messages, simply because they are already computed last time, and the new values of attributes were actually stored previously by the backtracking sub-system. It is thus convenient and efficient to just roll the component forward.
This technique requires that when backtracking is done, information of previous computation should not be discarded immediately. That information is discarded only when difference is found between the new sequence of messages received after the backtracking and the old sequence of messages received after the checkpoint is created.
It is not necessary to store all the backtracking information in memory. In case when a checkpoint is created a long time ago but backtracking is rarely required, the old states can actually be page out to secondary storage, or they can be compressed in the memory. If the saved objects support serialization, they can even be reused across different executions of the same system.
Not only the checkpointing process, the backtracking process can also be done on-the-fly (i.e., done when the other part of the system is still running). This idea is inspired by Dijkstra et al.'s on-the-fly garbage collection [1].
According to this strategy, when backtracking is requested, not all the objects in Ob are backtracked immediately. Instead, the backtracking sub-system first performs some necessary analysis, and then sets the backtracking bit. After this, the other parts of the system are allowed to continue with their job. This causes inconsistency between the backtracking sub-system's view and the view of the other parts, which must be tolerated carefully.
Since the other parts consider their states to be fully restored, they consider it safe to freely advance states with new messages. If no extra mechanism is employed, read operations on the states may return wrong results. Hence, on-the-fly backtracking must use read barriers to capture read operations. When an attribute is read but it has not been restored yet, it must be rolled back immediately (constant time because this only incurs an extra pointer assignment). This dependency between the read and the write (restore in this case) is characterized as flow dependency [2].
Moreover, write barrier must be used at the same time to capture any change on attributes' states. If an attribute is modified by the running program (called mutator in standard garbage collection terms), it should not be restored later. This dependency is characterized as output dependency [2].
Although on-the-fly backtracking is a challenging technique giving rise to some form of complication, it is well worth because of the performance gained. It also enables real-time backtracking (with some moderate real-time guarantees).
As a final remark, checkpoints that are guaranteed not to be used any more should be discarded as early as possible. This reduces memory consumption by allowing the Java garbage collector to release memory hold by those old objects. This responsibility is mostly placed on the system designers.
[1] On-the-fly garbage collection: An exercise in cooperation![]() . Communications of the ACM. 21(11):966-975. 1978. BIBTEXEndNote
. Communications of the ACM. 21(11):966-975. 1978. BIBTEXEndNote
[2] Compiler transformations for high-performance computing![]() . ACM Computing Surveys. 24(4):345-420. Dec. 1994. BIBTEXEndNote
. ACM Computing Surveys. 24(4):345-420. Dec. 1994. BIBTEXEndNote
[1] In programming languages, backtracking "is a strategy for finding solutions to constraint satisfaction problems." (Wikipedia) This strategy is implemented in Prolog.
[2] This definition of root set is analogous with that in most literature on garbage collection.
[3] To do this, it may be necessary to incorporate some C code through JNI.