Thomas H. Feng (tfeng@eecs)
Contents
Abstract
This project deals with a special kind of refactoring on arbitrary Java programs to make them support checkpointing in the sense of distributed model execution.
Checkpointing (and later rolling back to a previously taken checkpoint) is useful in many applications. This ability makes it possible for the applications to recover their previous state when they detect error. There are many possible kinds of errors that require this kind of backtracking. E.g., in software fault tolerance, an application may have to recover its previous state when serious exception occurs, which cannot be easily handled. The application may keep trying an operation until a correct result is derived. The following imaginary code illustrates this:
class C {
private byte[] buffer; // A state variable.
...
void doOperation() {
boolean succ = false;
Checkpoint checkpoint = createCheckpoint();
while (!succ) {
try {
operation(buffer);
} catch (Throwable t) {
rollback(checkpoint);
}
}
discardCheckpoint(checkpoint);
}
...
}
Here in the example, operation is considered
a harmful operation on its single argument: it may possible fail
without explicit cause or known recovery method.
buffer is a state variable maintained by class
C. For the program to well-behave, all state
variables must have well-defined semantics. Hence, the programmer
may decide to first create a checkpoint before doing the harmful
operation. If it goes wrong, the object of C
rolls back to the checkpoint, which means the values in
buffer are restored.
In this simple case, it is obvious that the programmer can copy the array instead of creating a checkpoint. However, in a more complex case where many state variables may be erroneously modified and the programmer cannot identify all those variables in advance, checkpoint is more appropriate.
This project tries to implement the checkpointing mechanism based on program analysis. Ideally, the programmer needs to know nothing about checkpointing when he/she creates the application. A tool is built to automatically analyze the application after it is created. This analysis identifies state variables, and refactors the changes on those state variables in a checkpointing manner, which can be controlled through an interface revealed to the programmer.
This project is placed in the context of Ptolemy II, a tool for heterogeneous modeling and execution. In Ptolemy II, a model is constructed with blocks, which are either directors or actors. A director is a unique entity in a model (or a sub-model residing in a larger model) that decides how it should work. It decides which domain the model is in (e.g., continuous time, discrete time, synchronous data flow, etc). If scheduling, buffering, or other mechanisms are required, the director also has implementation for them. Actors are building blocks of a model (or sub-model). Each atomic actor implements a basic computation with the input data, and possible produces some output data. Atomic actors may be grouped as composite actors. Actors are liked with each other with channels between an output ports and input ports.
Unlike some other modeling environments, directors and atomic actors in Ptolemy II are Java classes written according to some conventions. Those convensions are not important to our discussion. In this project, I treat those directors and actors as standard Java programs.
The problem to be solved in this project arises from distributed execution of Ptolemy II models. For a model to run distributedly, different components in it are placed on different computers connected with a network. As it runs, the model maintains its logic time, which defines the order of events occuring in the model. For performance reason, a component is allowed to advance its local logic time as far as no inconsistency is seen. If two components never exchanges messages, their local logic time can be substantially different.
Now support two components, which have not heard from each other for a very long time, now exchange a message. The message is received by the faster (meaning that its logic time is more in advance) component, but the message is tagged with a sending time less than the current time of the receiver. At this point, the receiver notices an inconsistency, and it must roll back. Because of the effect of that message, the computation on the receiver after the message time may be different, and the local state of the receiver should be re-computed.
Several challenges that this project must face includes:
Directors and actors are the entity of checkpointing. Since most of them are Java classes (except for those built by combining existing ones), a program analysis approach must be taken. In those classes, we cannot make model specific assumptions, because a designer of an actor is allowed to use any facility provided by Java.
As it is used in the context of efficient distributed execution, the run-time cost of this checkpointing should not outweight the performance we gain by runing a model distributedly.
Manual modification in the directors or actors is generally considered infeasible, because of the amount of code we have to inspect and rewrite.
There many existing software fault tolerance methods. A special kind, which is not fully studied, is addressed in this projects. It makes the following assumptions:
We are only interested in "soft states" -- the states represented as state variables in memory. Those states recorded in hard-disk is excluded from consideration. Soft states are identified in a Java program as private fields in classes. [1]
The checkpoint and all the backup states are also in memory. The application is not supposed to crash in a way that its memory is lost. [2] In those state variables, only assignments are the possible "harmful" operations. An assignment to a private integer field is considered possibly harmful if we are not sure of its effect. Similarly, an assignment to an element in a private array field is also considered possibly harmful. However, a read operation from a disk file to a private array is excluded from consideration for simplicity.
The application, e.g. the distributed execution engine, detects the point of error and request a rollback through an interface provided by the checkpointing facility. This detection is application-specific and cannot be automatically derived from the program structure.
The model analysis method is derived from Java program analysis, because in Ptolemy, actors (and directors) are directly written in Java. This makes analysis more challenging, because Java source analysis is usually harder than model analysis in a specific domain or in a specific modeling language (e.g., UML).
There always exists the tradeoff between power and complexity, which is important to our design.
The big picture of the proposed method is illustrated in Figure 2, “The big picture”. The important steps are made clear below:
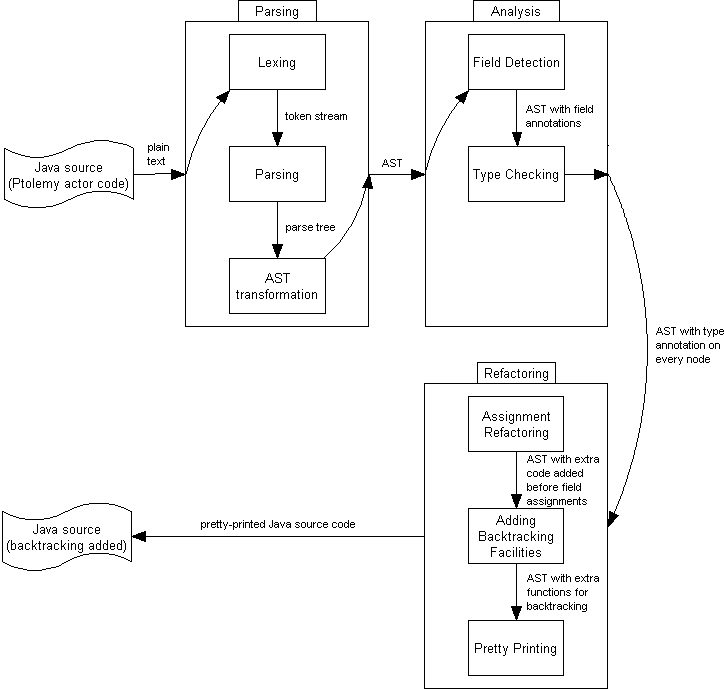
As the input being Java source written in plain text files, a parsing step is taken first. This is an ordinary program parsing, which is not interesting to our discussion. Currently, the parser in Eclipse is used. The internal steps taken by the parser is included in the figure for the sake of completion: a lexer divides a source file into a token stream; a parser parses the token stream and builds a parse tree; and an AST transformer converts the parse tree into an AST.
-
Analysis can then be done on the AST, which represents the complete structure of the Java code. This analysis is currently divided into two phases. (More phases may be added in the future.)
For checkpointing purpose, naturally, fields in each class must be detected. This is relatively simple: We simply walk through the AST and look for every class defined in the program. For each class found, loop over its members and look for
privatefields. We then annotate the AST with those field information.Three complications arise after a careful thought. Since Java allows nested classes, the following situations must be taken care of:
-
Non-
publicclasses (Bin the following example) in the same file (A.java):public class A { } class B { private int i; } -
Nested classes (
Bin the following class):public class A { class B { private int i; } } -
Anonymous classes:
new A() { private int i; };
In all the above cases, we want to derive field
i. In case 1,ibelongs to classB; in case 2, it belongs to classA$B; however, in case 3, it belongs to a class with a name that is compiler-dependent. -
-
After gathering enough information for each field, we are going to type-check the AST. We can safely assume that the source input contains no type errors (because it can be compiled with Java compiler before we do the refactoring). Hence, this type checking phase is mostly to derive appropriate types for each expression without producing any error. The intention is made clear with the following examples:
public class A { ... private int i; void func() { List list; ... ((A)list.get(0)).i = 1; ... } ... }Clearly, the old value of
ishould be recorded before this assignment operation is performed. The analyzer can easily detect that(A)list.get(0)returns an object ofAbecause of this explicit type conversion (note thatlist.get(0)returnsjava.lang.Object).public class A { ... private int i; void func() { B b; ... b.getA().i = 1; ... } ... }Unfortunately, in this second case, it is not so clear whether
ishould be monitored or not. To make a decision, the analysis must be taken across different classes, i.e., to analyzeBalso and discover the return type ofgetA(). After analysis is performed, assignments to fields can be refactored. In our case, this refactoring is to add code related to value backup before assignments.
When refactoring is done, the AST is then converted back into Java source, and Java compiler is used to compile the source into byte-code. If a compiler backend (e.g., soot) is provided, the output from AST may be byte-code directly.
An automatic approach is taken in the refactoring phase to transform the original code into code that supports checkpointing in an incremental sense. There are major differences between incremental checkpointing and the tradition serialization approach. In the latter scheme, in order to create a checkpoint, a complete snapshot is taken for the whole model, usually by means of serialization. The former, which is more efficient but also more challenging, records the incremental changes in the model. In this way, only the states changed between the checkpoint time and the rollback time are recorded.
The difference in performance and memory usage is made clear with an example. Assume that an actor in a model uses a big table to store its state. Using the serialization scheme, the whole table needs to be serialized and backed up at a checkpoint. However, using the incremental approach, only those elements changed after the checkpoint is created are backed up. If only very few elements are changed (though they might be changed many times), very few record entries are needed.
The refactoring done in the source code to enable this checkpointing is discussed in the following subsections.
The basic part of this refactoring to transform each assignment to state variables (once they are
detected) into a backup function. The backup function first records the previous state of the
affected variable, and then assign a new value to it. E.g., assume the following assignment to state
variable a:
a = 1;
It can be refactored as:
$ASSIGN$a(1);
The function $ASSIGN$a is a new function as follows:
private int $ASSIGN$a(int newValue) {
if (a checkpoint is created) and
(a is not backed up since the creation of the checkpoint)
record the current value of a;
return a = newValue;
}
In this way, assuming that every assignment to state variables (remind that they must be private) in the current class are precisely captured and transformed, they are always backed up before change.
One may use arrays as state variable, in which case the above solution does not quite work. In the following example, the first assignment is correctly refactored, but not the second or third:
a = new char[1][]; a[0] = new char[1]; a[0][0] = 'A';
As an improved solution, the refactoring should take arrays into account and generate different functions for different numbers of indices. This would correctly refactor the above example as follows:
$ASSIGN$a(new char[1][]); $ASSIGN$a(0, new char[1]); $ASSIGN$a(0, 0, 'A');
The following three functions are generated:
private char[][] $ASSIGN$a(char[][] newValue) {
...
}
private char[] $ASSIGN$a(int index0, char[] newValue) {
...
}
private char $ASSIGN$a(int index0, int index1, char newValue) {
...
}
Another difficulty arising from arrays is assigning them to local variables or passing them
as parameters to functions. In such cases, unless context-sensitive analysis is used, we have
to copy the whole array as serialization would do. Considier the following example, where
a is a state variable with array type:
int[] iArray = a; iArray[0] = 0;
The approach discussed above cannot detect this change in element 0. It is necessary to back
up a whenever it is assigned to a variable (or used as an actual parameter).